
Imagine a world where artificial intelligence could diagnose rare diseases years before a human doctor, predict the next global health crisis, or personalize a cancer treatment plan down to your individual cell. That world is absolutely within our reach today, but one massive hurdle stands in the way: patient privacy. You see, the fuel for this revolution is data, and specifically, sensitive patient data like your electronic health records. Researchers and AI developers need vast, realistic, and detailed datasets to train their life saving models. Yet, the moment we use a real patient’s information, we open the door to a data breach nightmare, risking major compliance violations like those under HIPAA. This is the ultimate Catch 22 in modern medicine. Thankfully, there’s an elegant solution to this challenge, a technological handshake between innovation and privacy: Synthetic Healthcare Data. It’s the key that unlocks the door to cutting edge AI without compromising your personal health information. We are going to explore how this amazing technology works and why it is rapidly becoming the gold standard for secure AI development in medicine.
1. Understanding Synthetic Healthcare Data and its Importance
We all know the power of data in our daily lives. From the ads we see to the movies Netflix suggests, data drives everything. In healthcare, the data is not just about preferences; it’s about life and death. But what happens when the need for highly detailed data conflicts directly with strict privacy laws?
1.1. The Critical Conflict: Data Utility Versus Privacy
Think about a pharmaceutical company trying to develop a new drug. They need patient records from a specific demographic to train their predictive models. If they use real records, they must go through a painfully slow, expensive, and legally complex process of de identification and ethical review. Even after all that work, traditional anonymization often destroys the subtle statistical relationships that make the data valuable for AI. It’s like blurring a masterpiece to protect the identity of the person who painted it, you save the person, but you lose the art. We need data utility, the ability to train high performing AI but we absolutely cannot sacrifice data privacy. This is where the magic of synthetic data enters the picture. It offers a way out of this conflict.
1.2. Defining Synthetic Healthcare Data
So, what exactly is Synthetic Healthcare Data? Simply put, it is information that is artificially generated by a computer algorithm, not collected from real patients. It’s “fake” data, but with a critical twist. This manufactured data is engineered to statistically mirror the real world dataset it was modeled after. Imagine a completely fictitious Electronic Health Record (EHR) for “Patient X” that looks and behaves just like a real one. It has the same distribution of lab results, the same patterns of diagnoses, and the same likelihood of developing certain conditions as a true patient population. However, because it was generated from scratch, there is no way to trace it back to a living, breathing individual. This is why it’s so vital for training AI models; it allows data scientists to work with realistic, high-fidelity datasets without the privacy burden of Protected Health Information (PHI). We can train a new diagnostic model on millions of realistic, yet completely fictional, patient profiles, making our systems smarter and safer for everyone. For more on protecting sensitive data, you might be interested in our deep dive on securing your assets with Post Quantum Cryptography: Securing PHI from quantum attacks.
2. Technical Methods: How Synthetic Healthcare Data is Generated
Generating quality synthetic data isn’t just about hitting a “random data” button. It is a highly sophisticated, technical process that leverages some of the most advanced algorithms in machine learning. The goal is to create data that is useful, or has high fidelity, but is also demonstrably safe and private. This requires an understanding of what truly makes the data tick.
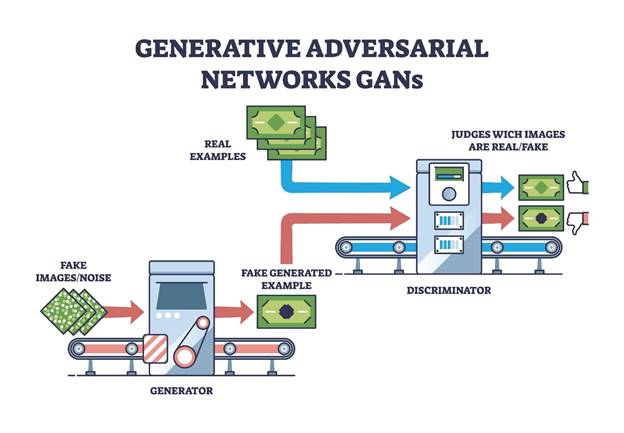
2.1. Generative Adversarial Networks (GANs) for Synthetic Healthcare Data
One of the most powerful and popular techniques for creating high-fidelity Synthetic Healthcare Data is using Generative Adversarial Networks, or GANs. Think of a GAN as a game played between two opposing AI networks: a Generator and a Discriminator.
Explore
- The Generator is an artist trying to create fake patient records (the synthetic data).
- The Discriminator is a detective trying to figure out if the records are real or fake.
The Generator constantly tries to fool the Discriminator, and the Discriminator constantly gets better at spotting the fakes. They learn from each other in a continuous feedback loop. Over time, the Generator becomes so good that the synthetic patient records it produces are virtually indistinguishable from real ones in terms of statistical structure and clinical coherence. This allows researchers to generate highly realistic synthetic EHR data for model training. The resulting dataset has all the necessary complexity and real world patterns needed for accurate AI systems. Want to see how complex AI models are being used in other parts of medicine? Check out 5 Applications of OpenAI’s AgentKit in Healthcare Automation. If you want to dive even deeper into the mechanics of this, one excellent resource that explores the use of GANs for creating synthetic EHR data is a tutorial published by the NIH which you can find here: Generating Synthetic Electronic Health Record Data Using Generative Adversarial Networks: Tutorial.
2.2. Differential Privacy: Mitigating Security Risks
While GANs ensure the realism of the data, another technique called Differential Privacy is often used to mathematically guarantee its privacy. Differential Privacy works by adding a carefully calculated amount of statistical “noise” or randomness to the data generation process. This noise is small enough that it doesn’t affect the overall statistical patterns for a large population, the utility remains high.

Explore
However, the noise is large enough that you cannot point to any single synthetic record and say with certainty what the corresponding real patient’s data looked like. It creates a mathematical shield. Essentially, if you run the same query on the original dataset and the synthetic dataset, the result is nearly identical, but the shield prevents an attacker from extracting information about any individual person. This is a critical step in providing a strong, quantifiable privacy guarantee, moving beyond vague promises of anonymity.
3. Legal and Operational Impact of Synthetic Healthcare Data
Data privacy in medicine is not just an ethical issue; it is a legally enforced mandate. When dealing with Synthetic Healthcare Data, its legal status is a key factor in its utility.
3.1. Navigating HIPAA and GDPR Compliance
In the United States, the Health Insurance Portability and Accountability Act (HIPAA) strictly governs Protected Health Information (PHI). In Europe, the General Data Protection Regulation (GDPR) sets an equally high bar. When a dataset is truly synthetic, meaning it was generated without a one to one mapping back to any real person and maintains a high level of privacy, it often falls outside the scope of PHI or “personal data.” This is a monumental advantage. It means institutions can use the data for research, testing, and AI training without having to adhere to the most stringent data sharing restrictions, fundamentally accelerating innovation. However, it’s not an automatic pass. The process for generating the synthetic data must be rigorous. Ethical and legal experts are still defining the nuances of how these synthetic datasets are regulated, especially when used for patient profiling in a clinical setting. To learn more about the legal and ethical considerations in this evolving field, a paper from the NIH’s PMC provides a great overview of the challenges: Synthetic data in medicine: Legal and ethical considerations for patient profiling.
3.2. Real World Applications: Augmentation and Acceleration
The theory is compelling, but where is Synthetic Healthcare Data making a real impact right now? Its applications are rapidly expanding across the healthcare ecosystem, from the smallest research labs to the largest hospital systems.
- Augmenting Rare Disease Datasets: Training an AI model to detect a rare disease is incredibly difficult because, by definition, there isn’t much real data available. Synthetic Healthcare Data provides a vital solution. Researchers can take those few real records and use generative AI to create a statistically similar synthetic dataset of thousands of records. This augmentation process provides the AI model with enough variety and volume to learn the subtle patterns of the disease, ultimately making the diagnostic tool more robust and accurate. This predictive power is vital in larger contexts, which we discuss in AI in Public Health Preparedness: Forecasting the next global health crisis.
- Accelerating Medical Device Testing: Before a new medical device like an AI powered diagnostic tool can be deployed in a hospital, it needs to be rigorously tested. By using Synthetic Healthcare Data, developers can test their models faster and earlier in the development cycle. They can simulate countless patient scenarios without ever putting a real patient at risk or violating any privacy mandates. This acceleration of testing drastically reduces the time it takes to get safe, innovative technology from the lab to the clinic, making the entire ecosystem more efficient. This focus on security and efficiency is also key to preventing third party risks, as detailed in AI Supply Chain Risk: Mitigating Vulnerabilities in Third Party Healthcare Vendors.
4. Strategic Challenges and Future Outlook
While Synthetic Healthcare Data is a game changer, it’s not without its challenges. The primary tension in the field remains a careful balance between how realistic the data is (fidelity) and how private it is (security).
4.1. The Trade Off: Balancing Fidelity Versus Security
Creating synthetic data that is too perfect can sometimes lead to models that don’t perform well in the real world. Why? Because real world data is messy, full of input errors, missing values, and outliers. If the synthetic data generation process cleanses the dataset too thoroughly, the resulting AI model might be accurate in the lab but stumble when faced with the chaos of a real hospital system. Conversely, making the data highly private by adding too much noise can also degrade its utility, causing the AI to miss those subtle, life saving signals. Experts in the field are constantly working on new evaluation metrics to measure both utility and privacy simultaneously, ensuring that the synthetic records are both safe for sharing and meaningful for machine learning. The goal is to maximize one without undue sacrifice to the other. For a scholarly discussion on how to assess this balance, you can refer to this comprehensive review from the NIH: A scoping review of privacy and utility metrics in medical synthetic data. Moreover, adopting a framework like Zero Trust can help safeguard all data access, whether real or synthetic, by ensuring no entity is trusted by default, a concept explored in our piece on Zero Trust in Healthcare.
4.2. Conclusion: The Future is Private, The Future is Synthetic
The revolution in healthcare AI depends entirely on our ability to responsibly handle sensitive patient information. For too long, the mandate of privacy has clashed with the imperative of innovation, creating a frustrating logjam in medical progress. Synthetic Healthcare Data provides the long awaited breakthrough, offering a way for researchers and developers to access high quality, realistic patient information without ever risking the re identification of a single individual. By leveraging sophisticated techniques like Generative Adversarial Networks and Differential Privacy, we can create data that is not only statistically sound but also legally and ethically safe. As this technology matures, we will see faster drug discovery, more accurate diagnostic tools, and a healthcare system that is, ironically, both more intelligent and more private than ever before. This dual benefit is not just a technological feat; it is a fundamental shift toward a more ethical and efficient future in medicine.
Frequently Asked Questions (FAQs)
1. Is Synthetic Healthcare Data considered Protected Health Information (PHI) under HIPAA?
Generally, no, truly synthetic data is not considered PHI because it cannot be traced back to a specific, identifiable person. Since it is generated from scratch and has no one to one link to real records, it usually falls outside the scope of strict privacy regulations like HIPAA and GDPR, provided the generation process is robust and verified against re identification risk.
2. How do we ensure that Synthetic Healthcare Data is realistic enough to train accurate AI models?
Realism, or data fidelity, is ensured through advanced generative models, primarily Generative Adversarial Networks (GANs). These systems are trained to mimic the complex statistical distributions, correlations, and temporal patterns found in the real source data. Rigorous validation against real world benchmarks, often using clinical experts to review the output, is essential to confirm the synthetic data’s utility.
3. Can synthetic data introduce new biases into AI models?
Yes, it absolutely can. If the original, real world dataset contains biases (e.g., underrepresentation of a specific ethnic group or condition), the synthetic data model will learn and replicate those biases. However, synthetic data also offers a powerful solution: researchers can deliberately augment the dataset by generating synthetic records for underrepresented groups, helping to correct the original bias and create fairer, more equitable AI tools.
4. What is the difference between Synthetic Healthcare Data and anonymized data?
Anonymized data is real patient data that has had all identifying markers (like names, dates, and locations) removed or masked. This process, however, often compromises the data’s utility because subtle but important correlations are lost. Synthetic data, on the other hand, is created from scratch to match the original data’s statistical properties. It was never real to begin with, offering a higher guarantee of privacy while maintaining greater analytical utility for AI training.
5. Is Synthetic Healthcare Data only for large organizations and Big Tech companies?
Not at all. While large companies are early adopters, the tools for generating Synthetic Healthcare Data are becoming more accessible, including open source options. This technology is incredibly beneficial for small research labs, startups, and academic institutions, as it allows them to access the volume and complexity of data required for modern AI research without the lengthy, prohibitive legal and logistical barriers of acquiring real patient data.
Leave a Reply